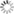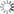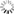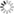Weakly Supervised Learning Unlocks Medical Imaging Insights

Image Source:
Phonlamai Photo/Shutterstock.com
By Becks Simpson for Mouser Electronics
Published September 2, 2021
Artificial Intelligence (AI) has advanced medical diagnostics from images by detecting and measuring
abnormalities faster and more accurately than human experts. Building high-quality AI models that generalize
across populations is imperative to improving patient outcomes and personalized treatments. However, AI
models have recently required a vast amount of data, and intricate dataset labels from which machines can learn.
Today, a branch of Deep Learning (DL) known as weakly supervised learning is helping physicians garner
more insights with less effort by reducing the need for complete, exact, and accurate data labels. Weakly
supervised learning works by leveraging more readily available coarse labels—such as at the image level
rather than segmentations of interest within the image—and allows pre-trained models and common
interpretability methods to be used. In the following, we’ll examine how managing data plays a role in
weakly supervised learning.
Labeling is Difficult in Medical Imaging
Labeling images is particularly challenging in the medical industry. To begin, labeled data is both limited and
hard to come by because medical images and data about the results/outcomes are generally stored in separate
systems. For example, images from computed tomography (CT) or magnetic resonance imaging (MRI) might be
available in hospital data, but the results of biopsies or tumor removals are typically stored in a pathology
lab—which is often a private clinic outside the hospital. Although it is possible to reconcile data and
labels for some pieces of data, accessing and aggregating data can become quite time-consuming, especially when
more than one private clinic is involved.
Additionally, finding and labeling signs of disease and its progress—called biomarkers—within images
has been notoriously time-consuming and complex because data must be labeled pixel by pixel, resulting in
thousands of labels. This is especially true in applications where an algorithm is expected to segment areas of
an image or produce specific localizations of a region, such as a lesion or surgical boundaries. This is often
costly because expert knowledge is usually required and labels are needed in three dimensions, as with MRI and
CT image volumes. Add these two downsides together, and it becomes an expensive exercise to generate labels for
imaging data. This also limits the likelihood of being able to outsource the labeling process.
Because of the expertise needed, the quality of the labels can vary and affect the final performance of the DL
model. Accuracy of labels is one issue here. Commonly, less-experienced radiologists or medical residents must
annotate data for training. Results are not as accurate compared to a clinician with decades of experience doing
the work. Inter-reader and intra-reader variability also come into play. The former describes how annotations
between readers will differ slightly. The latter referred to the instances when a single reader asked to segment
an image at two different points in time will also produce slightly different results.
Finally, human labeling can limit results as well. One benefit of machine learning is that the model can derive
insights that humans never could, and constraining labels to what humans input potentially limits results. For
instance, the AI would only learn to replicate what humans think for certain tasks, meaning they can
unintentionally reproduce a particular human's bias. Additionally, other features in other areas of the input
data can be predictive but discarded because they do not fall directly within the selected region of interest.
For example, indications of disease might be evident in surrounding tissue or a different organ nearby.
Leveraging Weakly Supervised Learning
In these cases, it is often more beneficial to use a coarser label such as whether an image contains cancer or
some other disease of interest and allow the model to find the most discriminative features (Figure
1). This is where weakly supervised learning comes in.
Figure 1: Example of automated annotation using weakly supervised learning
where the AI found predictive features that pathologists did not detect. (Source: Pathology Informatics
Team, RIKEN Center for Advanced Intelligence Project)
Weakly supervised learning describes the branch of DL that aims to reduce the number of labels or level of detail
required to produce a well-performing DL model. This approach can be roughly separated into three main
categories: Incomplete, inexact, and inaccurate labels. The word “roughly” is used here because
multiple labeling approaches can be used in a single dataset and because weakly supervised labeling aims to help
with any combination as required:
- Incomplete labels generally arise when part of the dataset is labeled, and the rest is not.
- Inexact labels include using the overall outcome for an image without needing to segment
the specific region of interest.
- Inaccurate labels, which stems from humans' lack of expertise and the ambiguity or
uncertainty between certain disease indicators.
Interestingly, inexact labels can be more useful than incomplete or inaccurate labels if a coarser, more readily
available label can be used to produce good results. Inexact labels are easier to get right because they
don’t require the same level of detail as other labels, and they are often easier to obtain, such as
extracting cancer stage as a label from a report to indicate a scan has cancer in it as opposed to manually
highlighting the cancerous regions on a 3D imaging. With inexact labels, the dataset will likely have more
labels available and at a higher level of accuracy. In particular, this reduces the need for a high level of
expertise to highlight all relevant pixels. It improves label accuracy because it’s easier to give a
binary answer than to detail all the features contributing to an outcome.
A popular way to leverage such inexact labels for the most common medical-imaging use cases such as detecting and
localizing regions of interest uses a two-step process:
- The backbone, such as training a DL model to predict the classes described by the inexact labels.
- The use of pixel-attribution methods—also known as saliency or interpretability methods—to
highlight the most relevant regions for the model’s decisions once it is developed to predict on
particular scans.
Figure 2 illustrates examples of the different gradient-based pixel attribution methods.
Figure 2: Two input images (goldfish and bear) with examples of the
gradient-based pixel attribution methods available for performing segmentation during weakly supervised
learning. (Source: TF Keras Vis on Github)
Convolutional Neural Networks as the Backbone
Because the medical use cases very often use imaging data, it’s no surprise that Convolutional Neural
Networks (CNNs) are the primary DL framework used as the basis for weakly supervised learning. CNNs work by
learning to reduce the millions of pixels in a medical scan—typically reducing a three-dimensional volume
to a low-dimensional representation—and then mapping that to class labels.
In weakly supervised learning, it is possible to combine approaches. For example, a new network could be trained
on your dataset (which affords benefits of other similar data sources). A pre-trained network could be used to
perform transfer learning on the new task. For example, ResNet50 and VGG16 are two CNN architectures trained on
millions of images found in everyday life. Although they were not trained on medical images, they can still be
useful because the convolutional filters learned in the earlier layers of the model tend to be generic features
such as lines, shapes, and textures, which are useful for medical imaging.
Using one of these models for transfer learning is as simple as removing the final class prediction layer and
reinitializing it with a layer representing the classes for the new medical imaging task. Even though the end
goal is to have outputs that highlight the relevant objects and regions of interest in the images, the first
step is merely to predict if those regions of interest exist in the image in the first place.
AI Interpretability for Weakly-Supervised Localization
Once the DL backbone is trained and can predict the classes of interest with good accuracy, the next step would
be to use one of the many AI interpretability methods to produce segmentations of the regions of interest. These
interpretability methods—also called pixel attribution methods—were developed to gain insight into
what a deep-learning model was looking at in an image when it made a certain prediction. The output is some form
of visualizations—often called saliency maps—which can be calculated in several different ways
depending on the end goal.
One of the most popular approaches is using gradient-based saliency maps. At its core, this involves taking the
output prediction and inspecting all the neurons that made up this output. Depending on the method, this
inspection can go all the way back to the first input layer—Vanilla Gradients. Or it could stop at some
later layer such as the last convolutional layer in the neural network architecture—GradCAM
(Figure 3). Other variations do different things such as produce smoother regions of interest,
improve the limitations of simpler variations, or generate tighter segmentations around the desired features.
Figure 3: GradCAM, an ML interpretability method that can be used to segment
features in weakly supervised learning, takes the gradients of the output class concerning the last
convolutional layer. (Source: Zhou et al from Computer Science and Artificial Intelligence Laboratory, MIT)
Conclusion
Until recently, identifying biomarkers in medical images required large volumes of intricately labeled imaging
data. However, techniques such as weakly supervised learning reduce the need for complete, exact, and accurate
data labels and unlocking insights that were too costly in time and expertise to attain. Weakly supervised
learning works by leveraging more readily available coarse labels—such as at the image level rather than
segmentations of interest within the image. It allows the reuse of pre-trained CNN models and then uses common
interpretability methods to highlight regions of interest based on the predicted class. These two points allow
models trained on medical imaging data for various applications without extensive, pixel-level annotations. This
saves time and money and potentially uncovers predictive features previously unknown to clinicians, which can
improve diagnostic accuracy and patient outcomes.
Author Bio
 Becks is a technical
lead for machine learning at Imagia, a Montreal-based startup putting AI in the hands of clinicians to drive
medical research. In her spare time, she also works with Whale Seeker, another startup using AI to detect whales
so that industry and these gentle giants can coexist profitably. She has worked across the spectrum in deep
learning and machine learning from investigating novel deep learning methods and applying research directly for
solving real world problems to architecting pipelines and platforms to train and deploy AI models in the wild
and advising startups on their AI and data strategies.
Becks is a technical
lead for machine learning at Imagia, a Montreal-based startup putting AI in the hands of clinicians to drive
medical research. In her spare time, she also works with Whale Seeker, another startup using AI to detect whales
so that industry and these gentle giants can coexist profitably. She has worked across the spectrum in deep
learning and machine learning from investigating novel deep learning methods and applying research directly for
solving real world problems to architecting pipelines and platforms to train and deploy AI models in the wild
and advising startups on their AI and data strategies.